Tính liên tục rất quan trọng đối với bất kỳ công ty nào vận hành trên nền tảng điện toán đám mây. Vì vậy, một kế hoạch phục hồi sau thảm họa (Disaster Recovery Plan) phù hợp sẽ giúp các tổ chức duy trì hoạt động trong trường hợp gặp sự cố hoặc bị tấn công.
Một trong những nhà cung cấp dịch vụ Cloud hàng đầu Amazon Web Services (AWS), cung cấp cho người dùng những tính năng giúp họ có thể xây dựng giải pháp phòng chống thảm họa của riêng mình. Mục đích bài viết này là bao quát khái niệm AWS Disaster Recovery Plan (DRP) cũng như 10 gợi ý tận dụng những chức năng trong AWS console để phòng ngừa và khởi tạo hệ thống sau thảm họa.
Tổng quan về AWS Disaster Recovery
Disaster Recovery Plan (DRP) là một bộ hướng dẫn chi tiết nhằm phục hồi hệ thống và kết nối mạng trong trường hợp gặp sự cố hoặc bị tấn công, với mục đích giúp tổ chức trở lại hoạt động nhanh nhất có thể.
Việc triển khai giải pháp khắc phục thảm họa ở hạ tầng truyền thống thường đòi hỏi chi phí thực hiện và bảo trì cao. Vì vậy, nhiều công ty tận dụng các công cụ và giải pháp khôi phục thảm họa của các nhà cung cấp dịch vụ đám mây, chẳng hạn như AWS hoặc Azure. Các giải pháp này cũng có thể được cung cấp bởi các bên thứ ba .
>> Ví dụ đối tác của AWS với các công ty như N2WS và Cloudberrylab, họ cung cấp các giải pháp khắc phục thảm họa phù hợp với AWS.
Người dùng AWS có thể nhận được một số lợi ích từ việc phát triển kế hoạch khôi phục và chuẩn bị sẵn sàng kế hoạch đó, chẳng hạn như:
- Giảm thiểu mất mát dữ liệu – bảo vệ dữ liệu quan trọng bằng cách thiết lập các khoảng thời gian sao chép
- Nhanh chóng khôi phục các ứng dụng quan trọng – giảm thiểu thời gian downtime
- Phân tán rủi ro – bằng cách sử dụng phục hồi sau thảm họa xuyên region của AWS
- Phản hồi nhanh chóng – yêu cầu thời gian tối thiểu để truy xuất tệp và dữ liệu từ đó khôi phục hoạt động
10 gợi ý để phát triển kế hoạch AWS Disaster Recovery
1. Xác định các tài nguyên và nguồn lực quan trọng
Những nguồn lực nào tạo nên cốt lõi của doanh nghiệp của bạn? Phân tích Tác động Kinh doanh (BIA) có thể giúp bạn hình dung về những khu vực nào có thể bị ảnh hưởng nhiều hơn trong trường hợp có mối đe dọa. Nó cũng có thể hướng dẫn bạn xem trước nguy cơ tiềm tàng của một thảm họa trong vận hành.
2. Xác định thời gian khôi phục (RTO) và điểm khôi phục (RPO)
Bạn nên biết tổ chức của bạn có thể chi trả được bao nhiêu trong thời gian downtime của hệ thống trước khi chịu những tổn thất tài chính không thể khắc phục được. Do đó, tính toán thời gian phục hồi là rất quan trọng cho một kế hoạch phục hồi thành công.Ngoài ra, bạn cần tính toán mức độ mất mát dữ liệu mà tổ chức của bạn có thể chấp nhận được trước khi chịu quá nhiều thiệt hại – đó là vai trò của điểm khôi phục. Ví dụ, nếu mất 4 giờ dữ liệu sẽ gây ra quá nhiều thiệt hại thì bạn cần tính toán sao cho RPO ít hơn 4 giờ.

Tham khảo thêm: https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/plan-for-disaster-recovery-dr.html
3. Chọn phương pháp AWS Disaster Recovery Plan (DRP) phù hợp
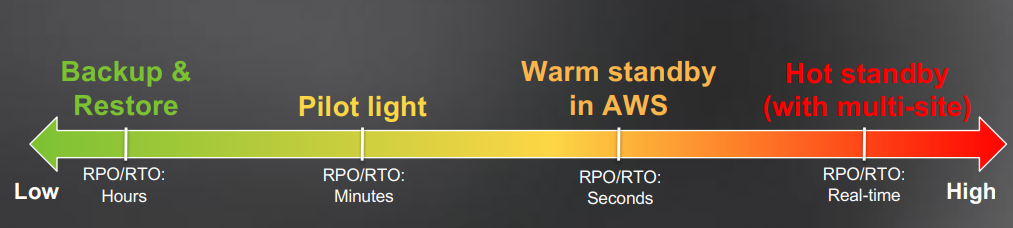
Có 4 phương pháp phục hồi chính mà bạn có thể chọn theo nhu cầu tổ chức và độ ưu tiên của bạn:
Backup and restore – bạn có thể sử dụng giải pháp được quản lý để sao lưu và khôi phục dữ liệu khi cần. Tuy nhiên, việc khôi phục có thể tiêu tốn nhiều thời gian và tài nguyên do hệ thống không giữ dữ liệu ở chế độ chờ.
Pilot Light – giữ phần cốt lõi của các ứng dụng và dữ liệu quan trọng luôn chạy để cho phép truy xuất nhanh chóng trong trường hợp xảy ra thảm họa.
Warm standby – sao chép các yếu tố cốt lõi của hệ thống và giữ cho chúng luôn hoạt động ở chế độ chờ. Trong trường hợp xảy ra thảm họa, bản sao này có thể được thăng cấp thành bản chính để duy trì hoạt động.
Hot standby – tạo một bản sao đầy đủ của dữ liệu và ứng dụng, triển khai nó ở hai hoặc nhiều vị trí hoạt động. Sau đó, bạn có thể phân chia lưu lượng giữa chúng, vì vậy trong trường hợp xảy ra thảm họa, hệ thống chỉ cần định tuyến lại mọi thứ đến một vùng an toàn.
4. Xác định và thực hiện các biện pháp bảo mật và khắc phục
Ví dụ, bạn có thể thực hiện các biện pháp kiểm thử như phần mềm giám sát máy chủ và kết nối mạng. Biện pháp khắc phục như các công cụ khắc phục có thể giúp khôi phục hệ thống sau thảm họa.
5. Kiểm tra kế hoạch của bạn trước khi triển khai
Lên lịch kiểm tra trong khi phát triển DRP của bạn có thể giúp bạn phát hiện ra các sai sót trước khi triển khai kế hoạch. Điều này có thể đảm bảo kế hoạch của bạn được hoàn thiện trước khi sự cố hoặc thảm họa xảy ra.
6. Lên lịch bảo trì
Bạn nên thường xuyên cập nhật kế hoạch của mình để theo kịp với những thay đổi của hệ thống.Hậu quả của một mối đe dọa là một bài học kinh nghiệm. Vì vậy nên điều chỉnh kế hoạch để ngăn chặn các cuộc tấn công hoặc các sự cố tiếp theo.
7. Sao lưu dữ liệu
Thường xuyên lên lịch sao lưu những gì bạn lưu trữ trên Amazon EC2 và EBS volumes có thể là chưa đủ để đối mặt với thảm họa. Bạn cần có quyền truy cập nhanh vào dữ liệu trong trường hợp xảy ra thảm họa. Một kế hoạch chi tiết và thường xuyên được cập nhật có thể giúp bạn khôi phục dữ liệu và sao lưu từ môi trường đám mây với thời gian downtime ngắn nhất.
8. Sử dụng sao lưu giữa các region
Trong quá trình phát triển kế hoạch, bạn cần quyết định những dữ liệu quan trọng được lưu trữ ở đâu. Để tránh làm cho toàn bộ hệ thống bị ngoại tuyến, bạn nên phân phối dữ liệu ở các Availability Zones (AZ) khác nhau trên khắp thế giới.
Ví dụ: bạn có thể sao chép chéo region cho S3. S3 sao chép dữ liệu mặc định đến nhiều nơi trong một region, tạo độ bền cao. Tuy nhiên, điều này không loại bỏ nguy cơ mất dữ liệu trong một region nhất định. Để ngăn chặn điều này, bạn có thể sử dụng tùy chọn sao chép giữa các region, tự động hóa việc sao chép dữ liệu vào một bucket được thiết kế sẵn trong một region khác.
Bạn cũng có thể sử dụng các global tables trong DynamoDB để triển khai cơ sở dữ liệu tổng thể trên nhiều region. Điều này kéo theo sự các thay đổi trên một số bảng bởi vì dữ liệu được phân chia ở các region khác nhau,nguy cơ mất dữ liệu được giảm thiểu.
9. Sử dụng xác thực đa yếu tố
Bạn nên giữ mật khẩu và thông tin đăng nhập của mình an toàn và ẩn khỏi những người dùng không được ủy quyền, thậm chí tắt các programmatic keys khi chúng được sử dụng để ngăn chặn các mối đe dọa nội bộ. Đặt xác thực đa yếu tố có thể đảm bảo quyền quản trị viên và các đặc quyền được thiết lập không rơi vào tay kẻ xấu.
10. Cân nhắc về dịch vụ phục hồi sau thảm họa (DRaaS) của bên thứ ba
Mặc dù có thể cố gắng thực hiện tất cả các bước của kế hoạch khắc phục thảm họa trong phạm vi tổ chức, nhưng có nhiều công ty nhỏ thiếu đội ngũ CNTT có chuyên môn sẽ cảm thấy dễ dàng hơn khi sử dụng giải pháp của bên thứ ba. Các công ty cung cấp dịch vụ DR không chỉ giúp các tổ chức phát triển, thực hiện và duy trì DRP của họ mà còn giúp họ có thể tập trung hơn vào việc phát triển doanh nghiệp của mình.
Các tùy chọn AWS Disaster Recovery
Giả sử bạn đã di chuyển lên đám mây bằng phương pháp rehosting và bạn sử dụng các phiên bản EC2 cho ứng dụng của mình. Có rất nhiều cách tận dụng các chức năng AWS để phát triển kế hoạch DR:
EC2 EBS Snapshots – cho phép bạn sao lưu một tập EBS.
EC2 AMIs – hoạt động tương tự như EBS snapshot, chứa siêu dữ liệu cho phiên bản EC2 và cho phép khôi phục toàn bộ phiên bản EC2.
Lambda – một sản phẩm không cần máy chủ cho phép bạn chạy code bên ngoài môi trường ứng dụng và đồng thời truy cập tài nguyên AWS. Bạn có thể sử dụng Lambda để tự động hóa các tác vụ như EBS snapshots.
Tổng kết
Việc phát triển và thực hiện kế hoạch khôi phục sau thảm họa cho AWS đòi hỏi một mức độ minh bạch nhất định, vì AWS không cung cấp giải pháp DR của riêng mình. Tuy nhiên, nền tảng cho phép người dùng xây dựng giải pháp DR tùy chỉnh bằng cách định vị lại một số tính năng và công cụ của nền tảng. Bài viết này cung cấp cho bạn một số tips và công cụ để phát triển kế hoạch khắc phục thảm họa của riêng bạn bằng cách tận dụng môi trường AWS.
Tham khảo: https://medium.com/@eddies_47682/10-tips-for-developing-an-aws-disaster-recovery-plan-a708f899a442
